|
ne fois n'est pas coutume, nous allons jouer avec une technologie qui n'est
pas mûre, et avec laquelle nous sommes loin de pouvoir développer pour mettre
en production... Mais il faut bien avouer que ça fait du bien de se faire du mal
avec ces jouets tout neufs, bien qu'inachevés.
Alors, avant d'entamer cet article, un petit mot d'avertissement obligatoire
:
Cet article démontre l'utilisation de technologies et d'outils qui ne sont
disponibles aujourd'hui qu'en version pré-alpha-preview-etc., et aucune date
fiable n'a été annoncée pour leur livraison en version finale. Il n'y a même
aucune garantie que celle-ci aura lieu un jour !
Ceci dit, des sources bien placées m'ont laissé entendre que tout cela fera
partie de la livraison Visual Studio Orcas/.NET 3.0/C# 3.0/VB 9.0, soit pas
avant 2007 au mieux.
Maintenant que vous voici mis en garde, nous pouvons entrer dans le vif du sujet.
Sommaire
Nous verrons :
- La construction d'un graphe de données provenant d'une base de données
avec DLINQ
- Les différences entre un chargement immédiat des données et un chargement
différé (lazy loading)
- La création de vues sur un graphe d'objets en mémoire avec LINQ (tris,
regroupements, projections)
- Comment reproduire ces opérations sans LINQ
- Comment filtrer et mixer des données provenant de la base avec des données XML
avec XLINQ
- Comment sauvegarder un jeu de données au format XML
- Comment effectuer une transformation sur des données en mémoire pour obtenir du
HTML
L'architecture de l'exemple est très simple :
- Une base de données
- Une couche d'accès aux données
- Une couche de présentation
Rappels sur Linq, DLinq, XLinq
Le projet Linq offre des fonctionnalités de
requêtage intégrées aux langages de programmation. Il sera ainsi possible
d'effectuer des requêtes typées sur des sources telles que des bases de données,
des documents XML ou même des graphes d'objets en mémoire. Cette technologie
s'appuie sur des innovations au niveau des langages de programmation comme C# 3
ou VB.NET 9, et sera portée sur d'autres langages .NET tel Delphi.
Note : Les exemples de cet article seront en C#, mais peuvent être adaptés en VB.NET 9.
DLinq est une extension de Linq qui permet de
requêter une base de donnée (aujourd'hui uniquement SQL Server) et de faire du
mapping objet-relationnel.
XLinq est une extension de Linq qui permet d'exécuter des requêtes sur des
documents XML, mais aussi de créer ou transformer simplement du XML.
Vous pourrez en apprendre plus sur ces technologies en vous reportant aux
liens en fin d'article.
Couche d'accès aux données
Nous allons maintenant commencer la construction de notre exemple
d'application par la couche d'accès aux données.
DLinq inclue un outil en ligne de commande nommé SQLMetal.exe qui génére du
code à partir d'une base de données. Ce code généré contient les classes qui
représentent la base de données et ses tables sous une forme orientée objets.
Cet outil simplifie grandement la tâche, et nous nous contenterons de l'utiliser
ici, mais vous pouvez très bien créer votre propre modèle objet à la main en
utilisant les classes et attributs fournis par le framework DLinq.
Dans notre cas, nous utilisons la base de données Northwind fournie avec SQL
Server.
Voici à quoi ressemble le code généré :

Voici notre DAO (Data-Access Object) :
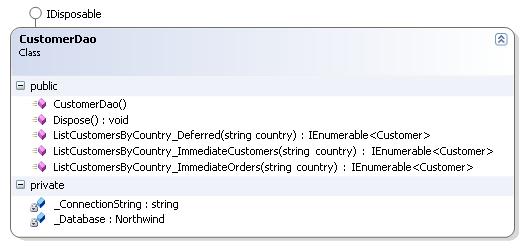
Chacune des méthodes démontre différentes façons de charger les données :
- ListCustomerByCountry_Deferred met en oeuvre le chargement différé (lazy
loading), c'est-à-dire que la méthode du DAO retourne une énumération de
clients, mais les données seront chargés à la volée lorsque l'on tentera d'y
accéder. Cela signifie donc que des appels à la base de données pourront
survenir en dehors de la méthode du DAO.
- ListCustomerByCountry_ImmediateCustomer permet de charger immédiatement les
données sur les clients, mais les données des détails (Orders) seront chargées
à la volée plus tard (chargement différé).
- ListCustomerByCountry_ImmediateOrders supprime le chargement différé des
clients et de leurs commandes : toutes les données sont chargées immédiatement
avant d'être retournées sous la forme d'une énumération. On a un paquet de
données prêtes à l'emploi en mode déconnecté.
Voici ce qui est opéré dans chacun des cas :
- On se contente de faire une requête simple :
return
from customer
in _Database.Customers
where
customer.Country == country
select
customer;
Cela produit ce qui se nomme une séquence, sur laquelle on pourra appliquer
des opérations de transformation ou d'énumération.
- On transforme l'énumération en liste :
return
(from
customer in
_Database.Customers
where
customer.Country == country
select
customer).ToList();
ToList() parcoure l'énumeration basée sur la séquence et retourne une List<T>
contenant les éléments de la séquence.
- On indique que l'on souhaite inclure les commandes et leurs détails dans
la séquence, puis ont créée une liste :
return
(from
customer in
_Database.Customers
where
customer.Country == country
select
customer).Including(customer => customer.Orders.Including(order =>
order.OrderDetails)).ToList();
C'est cette soultion qu'il faut employer si on souhaite travailler en mode
déconnecté, semi-connecté ou distant. Cela permet également de limiter les
appels à la base de données.
Pour permettre d'observer quand les appels à la base de données ont lieu,
nous allons tracer deux choses : les requêtes SQL envoyées par DLinq à la base
de données, et les débuts et fins de nos méthodes.
Pour tracer les appels SQL, nous allons demander à l'objet Northwind généré
par SQLMetal d'écrire dans la console. Cela peut s'écrire ainsi :
_Database =
new
Northwind(_ConnectionString)
{ Log = Console.Out
};
Il s'agit d'une nouvelle notation, nommée object initialization expression,
qui permet d'itinialiser les propriétés d'un objet. Ici cela n'apporte pas grand
chose, mais cela peut être utile dans d'autres contextes comme la construction
d'objet dans des requêtes Linq.
Le code que nous utilisons est équivalent à celui ci :
_Database =
new
Northwind(_ConnectionString);
_Database. Log = Console.Out;
Pour tracer les appels à nos méthodes, nous utiliserons une méthode
utilitaire très simple :
static
public
void LogMethod(bool
begin)
{
MethodBase
method;
method = new
System.Diagnostics.StackFrame(1).GetMethod();
Console.WriteLine((begin
? "Begin"
: "End")+"
- "+
method.DeclaringType.FullName+"."+method.Name);
}
Eh non, pas d'AOP cette fois-ci ;-)
Nous allons observer le comportement de nos différentes méthodes avec le code
suivant :
IEnumerable<nwind.Customer>
customers;
using (var
dao = new
CustomerDao())
{
customers = dao.ListCustomersByCountry_ImmediateOrders("Brazil");
}
foreach (nwind.Customer
customer in
customers)
{
Console.WriteLine("Customer:
" + customer.CustomerID);
foreach
(nwind.Order order
in customer.Orders)
Console.WriteLine("\tOrder:
" + order.OrderID);
}
Ce code récupère tout simplement la liste des clients, puis parcoure les
clients, ainsi que chacune de leurs commandes.
Voici ce que nous obtenons avec ListCustomersByCountry_Deferred :
DataAccess.CustomerDao.ListCustomersByCountry_Deferred - Begin
DataAccess.CustomerDao.ListCustomersByCountry_Deferred - End
SELECT [t0].[Address], [t0].[City], [t0].[CompanyName], [t0].[ContactName],
[t0].[ContactTitle], [t0].[Country], [t0].[CustomerID], [t0].[Fax],
[t0].[Phone], [t0].[PostalCode], [t0].[Region]
FROM [Customers] AS [t0]
WHERE [t0].[Country] = @p0
Customer: AROUT
SELECT [t0].[CustomerID], [t0].[EmployeeID], [t0].[Freight], [t0].[OrderDate],
[t0].[OrderID], [t0].[RequiredDate], [t0].[ShipAddress], [t0].[ShipCity],
[t0].[ShipCountry], [t0].[ShipName], [t0].[ShippedDate], [t0].[ShipVia],
[t0].[ShipPostalCode], [t0].[ShipRegion]
FROM [Orders] AS [t0]
WHERE [t0].[CustomerID] = @p0
Order: 10355
Order: 10383
...
Customer: BSBEV
SELECT [t0].[CustomerID], [t0].[EmployeeID], [t0].[Freight], [t0].[OrderDate],
[t0].[OrderID], [t0].[RequiredDate], [t0].[ShipAddress], [t0].[ShipCity],
[t0].[ShipCountry], [t0].[ShipName], [t0].[ShippedDate], [t0].[ShipVia],
[t0].[ShipPost
alCode], [t0].[ShipRegion]
FROM [Orders] AS [t0]
WHERE [t0].[CustomerID] = @p0
Order: 10289
Order: 10471
...
...
Nous observons ici qu'aucune requête à la base de données n'est executée dans
la méthode du DAO. Les requêtes sont exécutées tardivement, pour la liste des
clients, puis pour la liste des commandes de chacun des clients.
Voici ce que nous obtenons avec ListCustomersByCountry_ImmediateCustomers
:
DataAccess.CustomerDao.ListCustomersByCountry_ImmediateCustomers - Begin
SELECT [t0].[Address], [t0].[City], [t0].[CompanyName], [t0].[ContactName],
[t0].[ContactTitle], [t0].[Country], [t0].[CustomerID], [t0].[Fax],
[t0].[Phone], [t0].[PostalCode], [t0].[Region]
FROM [Customers] AS [t0]
WHERE [t0].[Country] = @p0
DataAccess.CustomerDao.ListCustomersByCountry_ImmediateCustomers - End
Customer: AROUT
SELECT [t0].[CustomerID], [t0].[EmployeeID], [t0].[Freight], [t0].[OrderDate],
[t0].[OrderID], [t0].[RequiredDate], [t0].[ShipAddress], [t0].[ShipCity],
[t0].[ShipCountry], [t0].[ShipName], [t0].[ShippedDate], [t0].[ShipVia],
[t0].[ShipPostalCode], [t0].[ShipRegion]
FROM [Orders] AS [t0]
WHERE [t0].[CustomerID] = @p0
Order: 10355
Order: 10383
...
Customer: BSBEV
SELECT [t0].[CustomerID], [t0].[EmployeeID], [t0].[Freight], [t0].[OrderDate],
[t0].[OrderID], [t0].[RequiredDate], [t0].[ShipAddress], [t0].[ShipCity],
[t0].[ShipCountry], [t0].[ShipName], [t0].[ShippedDate], [t0].[ShipVia],
[t0].[ShipPostalCode], [t0].[ShipRegion]
FROM [Orders] AS [t0]
WHERE [t0].[CustomerID] = @p0
Order: 10289
Order: 10471
...
...
Dans ce cas, seule la requête pour obtenir la liste des clients est executée
immédiatement, dans la méthode du DAO. Une nouvelle requête est exécutée
ultérieurement pour obtenir la liste des commandes de chacun des clients.
Voici ce que nous obtenons avec ListCustomersByCountry_ImmediateOrders :
DataAccess.CustomerDao.ListCustomersByCountry_ImmediateOrders - Begin
SELECT [t0].[Address], [t0].[City], [t0].[CompanyName], [t0].[ContactName],
[t0].[ContactTitle], [t0].[Country], [t0].[CustomerID], [t0].[Fax], (
SELECT COUNT(*) AS [C0]
FROM [Orders] AS [t1]
WHERE [t1].[CustomerID] = [t0].[CustomerID]
) AS [Orders], [t0].[Phone], [t0].[PostalCode], [t0].[Region]
FROM [Customers] AS [t0]
WHERE [t0].[Country] = @p0
ORDER BY [t0].[CustomerID]
SELECT [t1].[CustomerID], [t1].[EmployeeID], [t1].[Freight], [t1].[OrderDate],
(
SELECT COUNT(*) AS [C1]
FROM [Order Details] AS [t2]
WHERE [t2].[OrderID] = [t1].[OrderID]
) AS [OrderDetails], [t1].[OrderID], [t1].[RequiredDate], [t1].[ShipAddress],
[t1].[ShipCity], [t1].[ShipCountry], [t1].[ShipName], [t1].[ShippedDate],
[t1].[ShipVia], [t1].[ShipPostalCode], [t1].[ShipRegion]
FROM [Customers] AS [t0], [Orders] AS [t1]
WHERE ([t0].[Country] = @p1) AND ([t1].[CustomerID] = [t0].[CustomerID])
ORDER BY [t0].[CustomerID], [t1].[OrderID]
SELECT [t2].[Discount], [t2].[OrderID], [t2].[ProductID], [t2].[Quantity],
[t2].[UnitPrice]
FROM [Customers] AS [t0], [Orders] AS [t1], [Order Details] AS [t2]
WHERE ([t0].[Country] = @p2) AND ([t1].[CustomerID] = [t0].[CustomerID]) AND
([t2].[OrderID] = [t1].[OrderID])
ORDER BY [t0].[CustomerID], [t1].[OrderID], [t2].[OrderID], [t2].[ProductID]
DataAccess.CustomerDao.ListCustomersByCountry_ImmediateOrders - End
Customer: AROUT
Order: 10355
Order: 10383
...
Customer: BSBEV
Order: 10289
Order: 10471
...
...
Dans ce dernier cas, le dialogue avec la base de données a lieu intégralement
lors de l'appel de la méthode du DAO. Outre le fait que l'ensemble des données
est récupéré en une seule fois, seules trois requêtes sont effectuées, au lieu
de 1 + 1 par client + 1 par commande (si on accède aux détails des commandes), d'où un gain en performance et en dialogue
avec la base de données.
C'est le comportement que nous souhaitons dans le cadre de cet article : nous
souhaitons récupérer toutes les données pour ensuite ne
plus faire d'appels à la base de données.
Il va de soit que chacun de ces comportements est adapté à des situations
différentes, et qu'il n'y a pas un cas préférable dans l'absolu. Mais il faut
bien être conscient de ce qui se passe en arrière plan, faute de quoi on s'expose
à des surprises ou à de gros problèmes de performance.
Nota Bene : ceci n'est pas nouveau, et fonctionne déjà avec les
outils de mapping objet-relationnel disponibles dès aujourd'hui sur le
marché.
Couche de présentation
Création de vues en mémoire
Depuis notre couche de présentation (très sommaire !), nous allons créer des
vues sur les données fournies par la couche d'accès aux données, données que
nous conservons en mémoire.
Tri
Dans un premier temps, nous allons effectuer un tri.
Le plus simple est de trier sur une propriété particulière, ici CustomerName
:
void
DisplayCustomersSortedByName(IEnumerable<nwind.Customer>
customers)
{
// Sort
var result
=
from customer
in customers
orderby
customer.CompanyName
select
customer;
// Display
DisplayCustomers(customers);
}
Quid si on veut trier sur une autre propriété ? On tombe sur une des limites
de l'implémentation actuelle : les requêtes ne sont pas dynamiques, mais codées
en dur. Ainsi, le champ sur lequel nous trions ne peut pas être spécifié
dynamiquement. En tout cas pas simplement, pas pour l'instant.
Toutefois, on peut ruser en utilisant une expression lambda. La méthode suivante
prend par exemple une fonction qui lui permettra de déterminer sur quelle valeur
faire le tri :
void
DisplayCustomersSorted(IEnumerable<nwind.Customer>
customers,
Func<nwind.Customer,
Object>
orderKeySelector)
{
// Sort
var result
= customers.OrderBy(orderKeySelector);
// Display
DisplayCustomers(customers);
}
La fonction fournie comme orderKeySelector prend un client comme
paramètre et retourne la valeur d'une des propriétés de ce client.
Il est possible d'appeler cette méthode comme ceci :
DisplayCustomersOrdered(delegate
(nwind.Customer
customer) { return
customer.CompanyName;
});
Ou plus simplement avec une expression lambda :
DisplayCustomersOrdered(customer
=> customer.CompanyName);
Si on veut choisir la propriété dynamiquement, il faut encore ruser. On peut
par exemple utiliser la fonction suivante :
Object GetOrderKey(nwind.Customer
customer)
{
switch
(_OrderKey)
{
case
"CompanyName":
return
customer.CompanyName;
case
"City":
return
customer.City;
default:
return
customer.CustomerID;
}
}
et appeler :
_OrderKey =
"ContactName";
DisplayCustomersOrdered(GetOrderKey);
Regroupement
Voici comment effectuer un groupement par ville :
void
DisplayCustomersGroupedByCity(IEnumerable<nwind.Customer>
customers)
{
// Create groups sorted by city
name
var result
=
from customer
in customers
group
customer by customer.City
into cities
orderby
cities.Key
select
cities;
// Display
foreach (var
group in result)
{
Console.WriteLine(group.Key);
foreach
(var customer
in group.Group)
Console.WriteLine("\t"+customer.CompanyName);
}
}
Projection
Nous allons maintenant créer une vue présentant la liste des commandes de
l'ensemble des clients, avec pour chaque "ligne" des informations sur le client
telles que son nom et sa ville.
void DisplayOrders(IEnumerable<nwind.Customer>
customers)
{
// Create view
var result
=
from customer
in customers
from
order in customer.Orders
orderby
order.OrderDate
select
new {
order.OrderID,
order.OrderDate,
CustomerName
= customer.CompanyName,
CustomerCity
= customer.City,
};
// Display
ObjectDumper.Write(result);
/* Same as:
foreach (var order in result)
Console.WriteLine(
"OrderID="+order.OrderID+
"\tOrderDate="+order.OrderDate.Value.ToShortDateString()+
"\tCustomerName="+order.CustomerName+
"\tCustomerCity="+order.CustomerCity);
*/
}
Nous pourrions aussi imaginer une vue des clients avec par client le nombre
de commandes et le prix total de ces commandes :
void
DisplayCustomersWithOrderData(IEnumerable<nwind.Customer>
customers)
{
// Create view
var
result =
from customer
in customers
orderby
customer.CompanyName
select
new {
customer.CustomerID,
customer.CompanyName,
OrderCount
= customer.Orders.Count,
OrderTotal
= customer.Orders.Sum(order
=> order.OrderDetails.Sum(detail
=> detail.Quantity
* detail.UnitPrice))};
// Display
ObjectDumper.Write(result);
/* Same as this:
foreach (var customer in result)
Console.WriteLine(
"ID="+customer.ID+
"\tName="+customer.Name+
"\tOrderCount="+customer.OrderCount+
"\tOrderTotal="+customer.OrderTotal);
*/
}
Sans Linq et C# 3.0
Pour avoir une idée de ce qu'apporte Linq dans les cas que nous avons vus,
nous allons voir comment obtenir les mêmes résultats sans Linq, uniquement avec
C# 2.0.
Groupement
Voici le code pour effectuer le groupement sans Linq :
void
DisplayCustomersGroupedByCity_NoLinq(IEnumerable<nwind.Customer>
customers)
{
IDictionary<String,
IList<nwind.Customer>>
cities;
// Create groups sorted by city
name
cities =
new
SortedDictionary<String,
IList<nwind.Customer>>();
foreach
(nwind.Customer
customer in
customers)
{
IList<nwind.Customer>
cityCustomers;
if
(!cities.TryGetValue(customer.City,
out cityCustomers))
{
cityCustomers
=
new
List<nwind.Customer>();
cities[customer.City]
= cityCustomers;
}
cityCustomers.Add(customer);
}
// Display
foreach (KeyValuePair<String,
IList<nwind.Customer>>
city in cities)
{
Console.WriteLine(city.Key);
foreach
(var customer
in city.Value)
Console.WriteLine("\t"+customer.CompanyName);
}
}
Ce code est un peu plus complexe et moins lisible, mais reste accessible. On
imagine bien que les choses commencent à se compliquer avec des requêtes plus
complexes.
Projection
Voici comment créer une vue sur les commandes sans Linq :
void
DisplayOrders_NoLinq(IEnumerable<nwind.Customer>
customers)
{
List<OrderView>
orders;
// Create view
orders =
new
List<OrderView>();
foreach
(nwind.Customer
customer in
customers)
{
foreach
(nwind.Order
order in customer.Orders)
orders.Add(new
OrderView(order.OrderID,
order.OrderDate.Value,
customer.CompanyName,
customer.City));
}
// Sort
orders.Sort(new
Comparison<OrderView>(delegate
(OrderView view1,
OrderView view2) {
return
view1.OrderDate.CompareTo(view2.OrderDate);
} ));
// Display
ObjectDumper.Write(orders);
/* Same as:
foreach (OrderView order in orders)
Console.WriteLine(
"OrderID="+order.OrderID+
"\tOrderDate="+order.OrderDate.ToShortDateString()+
"\tCustomerName="+order.CustomerName+
"\tCustomerCity="+order.CustomerCity);
*/
}
On notera que l'on passe ici par une classe OrderView qu'il faut bien
entendu créer... c.f. code source complet.
XLinq
On peut utiliser XLinq pour plusieurs choses. Voici quelques exemples.
Mixer et filtrer des données provenant de la base avec des données XML
void
DisplayWebCustomers(IEnumerable<nwind.Customer>
customers)
{
const
String WebCustomersData
=
@"<WebCustomers>
<Customer ID='FAMIA'
EMail='info@arquibaldo.br' WebSite='http://arquibaldo.br' />
<Customer ID='HANAR'
EMail='me@hanari.com' WebSite='http://www.hanari.com' />
<Customer ID='QUEDE'
EMail='him@freemails.br' WebSite='http://www.brazilnet/delicia' />
<Customer ID='WELLI'
EMail='sales@wellington.br' WebSite='http://www.wellington.br' />
</WebCustomers>";
// Load XML
var
webCustomers =
XElement.Parse(WebCustomersData);
// Create view
var result
=
from customer
in customers, webCustomer
in webCustomers.Elements()
where
customer.CustomerID
== webCustomer.Attribute("ID").Value
select
new {
ID
= customer.CustomerID,
Name
= customer.CompanyName,
EMail
= webCustomer.Attribute("EMail").Value,
WebSite
= webCustomer.Attribute("WebSite").Value};
// Display
ObjectDumper.Write(result);
}
Uniquement les clients figurant à la fois dans le XML et dans la base de
données sont conservés, et enrichis avec une addresse e-mail et un site web.
Sauvegarder un jeu de données au format XML
Le code suivant génère du XML que l'on peut transformer, sauvegarder,
transférer, ... :
void
DisplayAsXml(IEnumerable<nwind.Customer>
customers)
{
// Create XML
var xml
=
new
XElement("Customers",
from customer
in customers
where customer.City
==
"Rio de Janeiro"
select
new
XElement("Customer",
new
XAttribute("ID",
customer.CustomerID),
new
XAttribute("Name",
customer.CompanyName)
)
);
// Display
Console.WriteLine(xml);
}
Générer du XHTML
Au même titre qu'on peut générer du XML, on peut très bien générer du XHTML
pour obtenir une présentation web des données :
void DisplayAsXhtml(IEnumerable<nwind.Customer>
customers)
{
#region
Create HTML
var header
=
new [] {
new
XElement("th",
"Customer id"),
new
XElement("th",
"Customer name"),
new
XElement("th",
"Country"),
new
XElement("th",
"City"),
};
var rows
=
from customer
in customers
select
new
XElement("tr",
new
XElement("td",
customer.CustomerID),
new
XElement("td",
customer.CompanyName),
new
XElement("td",
customer.Country),
new
XElement("td",
customer.City)
);
var html
=
new
XElement("html",
new
XElement("body",
new
XElement("table",
new
XAttribute("border",
1),
header,
rows
)
)
);
#endregion
Create HTML
#region
Display
Console.WriteLine(html);
String
filename =
Path.ChangeExtension(Path.GetTempFileName(),
"html");
File.WriteAllText(filename,
html.ToString(),
Encoding.UTF8);
System.Diagnostics.Process.Start(filename);
#endregion
Display
}
Conclusion
Nous n'avons fait qu'effleurer les possibilités offertes par Linq et
compagnie, mais nous avons déjà pu voir quelques services que cela pourra nous
apporter. Il y aura de
quoi faire bien d'autres articles sur le sujet, d'autant plus que ces
technologies vont encore beaucoup évoluer avant leur sortie officielle.
Linq introduit de nouveaux concepts directement dans le langage. Vous noterez bien
que jusqu'ici seul le langage a été enrichi, la plate-forme .NET n'as pas eu
besoin d'évoluer. Le compilateur utilisé est C# 3.0, mais le framework est en
version 2.0 non modifiée. On peut cependant s'attendre à des évolutions du
framework par la suite pour d'autres nouveautés, et à terme, Linq ne
fonctionnera probablement plus sur .NET 2.0.
On peut remarquer que le niveau de complexité est toujours de plus en plus élevé, avec de nouveaux mots-clefs et
beaucoup de concepts nouveaux et pas toujours simples à aborder.
Si on se projette un peu plus loin, il ne reste plus à Microsoft qu'à intégrer Linq dans Atlas pour qu'on puisse
faire des requêtes sur des données dans le navigateur sans faire d'appel au
serveur... D'ici là, vous pouvez utiliser
TrimQuery et AMASS.
Qui est Fabrice Marguerie ?
Fabrice Marguerie est architecte .NET chez
Alti. Fabrice intervient sur des missions
de conseil, de conception ou de réalisation. Il a conçu et réalisé le
framework .NET d'Alti.
Fabrice rédige un weblog en anglais :
http://weblogs.asp.net/fmarguerie
et gère le site
SharpToolbox.com qui référence les
outils de développement pour .NET.
Sa société :
Alti
Créée en 1995, Alti est une société
de conseil et d'ingénierie en
systèmes d'information. Alti c'est
aujourd'hui 500 personnes et un
chiffre d'affaire de 49.1 M€. Alti développe ses expertises (.NET, Java, objet et
UML, SAP, etc.) au sein de centres de compétences
dédiés. Alti est partenaire Microsoft
depuis 1994. |

|
|
